Data Protection Methods
An organization’s data is one of its most highly valued assets. Financial information is central to the business operations of banking institutions, while healthcare information is important to hospitals and medical organizations. Generally speaking, protecting data and assuring confidentiality, integrity, and availability are central to information security practices. There are several general concepts and categories of data protection that should be understood.
Data Backups
A fundamental process in data protection is data backup. Backup data is a second, duplicate copy of the data stored in a different location from the primary data set. There are many reasons for creating backups. Backups help ensure the availability of data and reduce downtime in a variety of ways. For example, if ransomware or some other cyber attack renders data in the production environment unusable, a secure backup ensures that the organization can still operate relatively smoothly. Similarly, when data is lost by inadvertent disposal, having a recoverable backup may save critical business operations or avoid regulatory issues. Data backups are also invaluable in support of audits and investigations. There are several methods of creating and maintaining backups. Each depends on data sensitivity, information risk, and business requirements.
The location of data backups is also dependent on the assessment of risk and data sensitivity. Data can be backed up off-site on physical media like tapes. There are data backup services online or through cloud service providers.
The Traditional Backup Cycle
Data backups can be processed in a variety of possible iterations. These include full back- ups, incremental backups, differential backups, and journaling. Most organizations will need to make backups, store data, and restore information from all of these backup types.
Full Backups
Typically, a full backup might be accomplished periodically, such as weekly or monthly, for example. If proper hygiene of full backups is not accomplished, the storage requirements increase, as each copy increases the volume by 100 percent unless the older versions are deleted. Other than making the first full copy of a database, another reason to do a full backup might be in advance of a major system upgrade or migration. The full data backup is a precautionary tactic just in case something goes wrong and data recovery is needed. In the event of production data loss, the full data backup likely results in a gap, depending on the timing of the last full backup. In addition to being the most expensive option, a full backup is the slowest method for backing up data and recovering it into the production environment.
Differential Backups
Once the initial full backup is done, subsequent copies can be made in differential iterations. This is more cost-effective than performing a full backup because only data that has changed since the last full backup is copied. The advantage of a differential backup is that it shortens the restore time compared to a full backup and is less costly to perform. However, if the differential backup is performed too often, the storage requirement builds and may exceed the full backup volume.
Incremental Backups
This type of backup is most cost-effective, as only the data that has changed since the last full or differential backup is stored. Incremental backups can be run ad hoc or more Often than differential backups to economize storage space. The main disadvantage is that if a restore is attempted from the incremental backup, the time to restore can be lengthy, as each incremental volume has to be processed.
Journaling
Journal files are created for each update. They record metadata about the transaction and are created during the backup process. It is important to store the journal files separately from the data backups. Both are needed to complete a full restoration from a backup free of data corruption.
Related Product : Personal Data Protection & General Data Protection Regulation Training & Certification
Other Backup Approaches
In addition to the traditional methods for creating data backups, there are many other technologies and processes of which the security professional must be aware. As compute and storage environments evolve from on-site data centers to cloud and virtual environments, the choices for backups continue to expand. An organization needs to establish and manage a portfolio of complementary processes and locations for data backup. It is important that the security professional understands the risk of using each solution and the accountability that remains with the organization as traditional backups are augmented by completely outsourced solutions.
Database Mirroring
Using database mirroring, a copy of the information is kept on two different servers, the principal and the mirror. The mirrored copy is a secondary copy and is not active until required. The mirrored copy is consistently synchronized with the principal database. The process assures maximum data availability and improves data recovery in the event there is corruption or loss of data in the primary database.
Snapshots
This technology is a process of making a virtual copy of a set of files, directories, or volumes as they appeared in a particular point in time. Snapshots are not backups. They are point-in-time copies. They lack the metadata that is included when using traditional backup applications. Using snapshots for backups helps storage systems because they do not degrade application performance during the backup process. They are useful for efficiently backing up large amounts of data.
Availability Zones
In cloud computing technology, these designations are isolated locations within geo- graphic regions of the cloud service provider’s data center. The choice of locations for availability zones is based on business requirements, which might include regulatory compliance and proximity to customers. The storage of backups replicated in multiple availability zones can decrease latency or protect resources.
Vaulting
An organization can send data off-site to be protected from hardware failures, theft, and other threats. The service can compress and encrypt the data for storage in the remote vault. Data is usually transported off-site using removable storage media such as magnetic tape or optical storage. Data can also be sent electronically via a remote backup service. The locations of data vaults vary. They can be underground in converted mines or decommissioned military sites. They can also be located in free-standing dedicated facilities or in a properly secured location within a building with other tenants.
Physical Media Backup
A couple of common media used for backups are magnetic tape and computer disk. Because the physical media are able to store the data without a connection to network resources, the removable nature allows physical media to be used for transportation of stored data from one location to another. This portability introduces the security risk of losing the assets or having them stolen, for instance, during transfer. Encryption of the data at rest on the media is required to keep the data as secure as possible.
Magnetic backup tapes are usually the most cost-effective, but the retrieval of the data is slower and more complex because of how data is written to the media. Disk-based solutions like external hard drives, network-attached storage, or even dvds reduce read errors and increase restoration speed. However, several of the options are more expensive than tape backup. A combination of tape and disk media is usually employed in a tiered storage arrangement. Disk storage is used first for data that is required to be restored often. Tape media is used to store data with more long-term storage plans and archiving.
LAN-Free and Server-Free Backup to Disk
Different from local storage options like USB hard drives or connected devices, local area network–free (LAN-free) and server-free options like storage area networks (sans) are faster and more efficient solutions for large amounts of data. The LAN-free or server-free architecture still requires connection to the devices with databases or media files. This is usually accomplished with the Fibre Channel protocol and media for high-speed data transfer that does not compete with regular network traffic. In most cases, LAN-free or server-free backup is used in tandem with physical media and disk storage in a complete portfolio of secondary data stores.
A SAN is a dedicated high-speed network or subnetwork that interconnects and presents shared pools of storage devices to multiple servers. It moves storage resources off the common user network and reorganizes them. This enables each server to access shared storage as if it were a drive directly attached to the server. Sans are primarily used to enhance storage devices, such as disk arrays and tape libraries, accessible to servers but not other devices on the LAN. Not to be confused with sans, network-attached storage (NAS) is file-level computer data storage servers connected to a computer network providing data access to a heterogeneous group of clients. The storage servers are specialized for serving files by their hard- ware, software, or configuration. They are networked appliances that contain one or more storage drives, often arranged into logical, redundant storage containers. NAS removes the responsibility of file serving from other servers on the network.
Generally speaking, a NAS system uses TCP/IP as the communication protocol. A SAN uses Fibre Channel. Fibre Channel is a high-speed data transfer rate technology, up to 4 Gbps. Fibre Channel is also very flexible. It connects devices over long distances, up to 6 miles when optical fiber is used as the physical medium. Optical fiber is not required for shorter distances, however, because Fibre Channel also works using coaxial cable and ordinary telephone twisted pair.
Data Deduplication
Protecting data includes not storing unneeded data. A type of excess data that organizations struggle with is duplicated data, or redundant data. To reduce the amount of duplicate data, security professionals can implement deduplication processes and use tools to remove duplicate information. This will help data owners and processors efficiently store, back up, or archive only the amount of data required. Duplicate data can be an entire database, a file folder, or subfile data elements, or can be implemented in the storage environment at the block level. Tools can be used to identify duplication of data and automate data deduplication. Figure 2.7 illustrates high-level considerations for the basic functions of deduplication tools. Typically, the environment is scanned and chunks of data are compared. The deduplication happens because the chunks are assigned identifications, compared through computing software, and cryptographic hashing algorithms to detect duplicates. When data is identified and verified as duplicate, the tools insert
A pointer or stub and a reference to the location of the primary source of the data. The duplicate data volume is removed, storage requirements are lessened, but awareness remains for where the data can be accessed.
Disaster Recovery Planning
Data availability is often given too little attention in comparison with confidentiality and integrity as security concerns. Business resiliency, continuity of operations, and recovery from disasters are critical responsibilities that rely on data availability even in the event of anthropogenic or natural disasters. Of the anthropogenic variety, disaster recovery is increasingly important in light of cybersecurity attacks aimed at disrupting the business, total destruction of computing assets through ransomware, or theft of all copies of the data. Organizations must have a disaster recovery plan (DRP) in place that outlines backup strategies and prioritization of data recovery for business critical systems.
The plan must be tested periodically to determine whether the plan to restore is actually operational, and personnel should be trained to take the actions required. Although dependent on the industry and regulatory requirements, testing should be performed no less than annually. 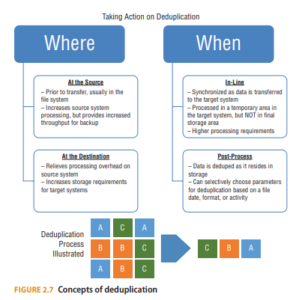
Note Cloud computing solutions have begun to change the way disaster recovery is achieved within organizations. Because cloud service providers configure assets as virtual- ized computing platforms with redundancy across geographic distances, primarily for high availability, disaster recovery is more of an instantaneous, transparent shifting of computing platforms and data sources invisible to the customer. An organization with assets in the cloud would not require, for instance, an on-premises data center as a recovery site to the cloud plat- form in which the organization is a tenant.
Disk Mirroring and Storage Replication
Disk mirroring is a technique in which data is written to two duplicate disks simultaneously to ensure continuous availability. A mirrored volume is a complete logical representation of separate volume copies. The same data is written to disk storage on separate Areas, or partitions, on the same disk volume to establish fault tolerance. In the event of a disk drive failure, the system can instantly switch to the other disk without any loss of data or service. Disk mirroring is used commonly in online database systems where it’s critical that the data be accessible at all times. Disk mirroring provides assurance of data resiliency when one copy of the data is lost or corrupted.
Storage replication differs from disk mirroring in that the second and subsequent backup copies are stored in geographically different locations. It is a managed service in which stored or archived data is duplicated in real time over a SAN. The purpose is
The same in terms of data resiliency as part of the overall disaster recovery process. Other terms for this type of service include file replication, data vaulting, data replication, and remote storage replication. The expression can also refer to a program or suite that facilitates such duplication.
The most commonly used type of disk mirroring is in RAID 1 configurations. RAID is short for redundant array of independent disks. RAID storage provides fault tolerance through the use of multiple disks. This improves overall performance and increases storage capacity in a system. In older storage devices, less space was available because they used a single disk.
RAID allows you to mirror the same data redundantly on separate disks in a balanced way. Personal computers do not usually use RAID, but servers often do. The technique RAID uses to spread data over one or more disks in the same array is known as striping; RAID also offers the option of reading or writing to more than one disk at the same time to improve performance. The disks in a typical RAID array appear to be a single device, even though the array consists of multiple disks with an increased amount of storage over just a single disk. Although the most common type of disk mirroring is RAID 1, there Are many different RAID architectures, called levels. RAID levels greater than RAID 0 provide protection against unrecoverable sector read errors, as well as against failures of whole physical drives. The most often-discussed RAID levels include the following:
- Level 0: Striped disk array without fault Provides data striping (spread- ing out blocks of each file across multiple disk drives) but no redundancy. This improves performance but does not deliver fault tolerance. If one drive fails, then all data in the array is lost.
- Level 1: Mirroring and Provides disk mirroring. Level 1 provides twice the read transaction rate of single disks and the same write transaction rate as single disks.
- Level 2: Error-correcting Not a typical implementation and rarely used, Level 2 stripes data at the bit level rather than the block level.
- Level 3: Bit-interleaved Provides byte-level striping with a dedicated parity disk. Level 3, which cannot service simultaneous multiple requests, also is rarely used.
- Level 4: Dedicated parity A commonly used implementation of RAID, Level 4 provides block-level striping (like Level 0) with a parity disk. If a data disk fails, the parity data is used to create a replacement disk. A disadvantage to Level 4 is that the parity disk can create write bottlenecks.
- Level 5: Block interleaved distributed Provides data striping at the byte level and also stripe error correction information. This results in excellent performance and good fault tolerance. Level 5 is one of the most popular implementations of RAID.
- Level 6: Independent data disks with double parity. Provides block-level striping with parity data distributed across all
- Level 10: A stripe of Not one of the original RAID levels, multiple RAID 1 mirrors are created, and a RAID 0 stripe is created over these.
There are other nonstandard RAID levels that occur because some devices use more than one level in a hybrid or nested arrangement. Other levels exist as proprietary configurations based on some vendor products.
The type of disk mirroring implementation will depend on the required level of redundancy and performance for the organization. The RAID levels provide a different balance among the goals that the organization has for data: reliability, availability, performance, and capacity.
Data States and Protection
Data exists in a range of states, and some states are more active than others. For exam- ple, data can be inactive (at rest), active (in use), or moving from one place to another (in transit). Data must be protected in all of its states, and doing so requires specific approaches.
Data at Rest
Data is considered inactive when it is stored on the cloud, on physical media backups, or on a device such as a laptop, mobile phone, or USB removable drive. The data is “at rest,” meaning that there is no active processing or transfer from device to device or across networks. Data at rest can be employed across the entire volume of the hard drive, called full disk encryption. A couple of approaches to encrypting the entire hard drive are worth noting.
- The Trusted Platform Module (TPM) is a microcontroller chip integrated into the computer hardware that provides a crypto-processor. The cryptographic keys are incorporated in the
- Self-encrypting hard drives (seds). With built-in encryption features, the con- tents of a SED are always The encryption key is included but should be stored separately and updated on a regular basis. This approach offers a more user-friendly experience, as the encryption does not impact productivity or performance.
A more granular approach allows encryption to be applied at the individual file level, called file-level encryption. Tools for information rights management (IRM) provide a key benefit. File-level encryption is a tailored data protection strategy that may provide additional protection from unauthorized access to a file on a hard drive in the event the full disk is decrypted.
Data in Transit
Data in transit is considered to be at increased risk. Described as data in motion too, data in transit is any data that is actively moving from a point of origin to a destination across networks, including trusted, private networks. The data can also be transferred across untrusted networks through the Internet and to the cloud, as examples. The following are some leading security protocols used to protect data in transit:
- Web access: HTTPS
- File transfer: FTPS, SFTP, SCP, web dav over HTTPS
- Remote shell: SSH2 terminal
- Remote desktop: rad min, RDP
- Wireless connection: WPA2
Link encryption is a method of data in transit security where the traffic is encrypted and decrypted at each network routing point (e.g., network switch, or node through which it passes). This continues until the data arrives at its final destination. The routing information is discovered during the decryption process at each node so the transmission can continue. The message is then encrypted. Link encryption offers a couple of advantages:
- Less human error because the process of encryption is
- Traffic analysis tools are circumvented, and attackers are thwarted because a continuous communications link with an unvarying level of traffic maintains the encryption
End-to-end encryption is another data-in-transit method. This type of system of communication ensures that only the sender and recipient can read the message. No eavesdropper can access the cryptographic keys needed to decrypt the conversation. This Means that even telecom providers, Internet providers, or the provider of the communication service cannot access the cryptographic keys needed to decrypt the conversation.
Data in Use
While an authenticated user is accessing a database or an application, data is in a volatile state. Active data stored in a non-persistent state is known as “data in use”. The data is typically used in RAM, CPU caches, or CPU registers to perform the transactions and tasks the end user requires. Encryption is not necessarily relevant or a primary control used with data in use, but it can be complementary to other controls. Data in use, presumably by an authorized user, underscores the importance of authentication, authorization, and accounting to control and monitor access to sensitive assets. Once a hacker has stolen valid credentials, many controls like encryption are rendered ineffective because the intruder has access like an insider. These types of issues are discussed further in Chapter 3.
Encryption
Sensitive data at rest and in transit should be protected. The ability to render data unusable to unauthorized individuals in the event the data is lost, stolen, or inadvertently accessed is essential for data protection. One of the mechanisms for accomplishing this is encryption. In doing so, encryption also provides confidentiality. The encryption process must be a central part of the entire layered defense strategy in an organization.
In selecting an encryption methodology, the security professional has to take into account the increased computational overhead of the encryption process and the management of the cryptographic process. It is important to use only widely accepted encryption algorithms and widely accepted implementations, like those found in NIST SP
800-38A,“Recommendation for Block Cipher Modes of Operation: Methods and Techniques” (https://csrc.nist.gov/publications/detail/sp/800-38a/final).
Although encryption is a powerful tool, other security controls are still needed to develop an entire baseline set of controls. In many regulatory environments and industry requirements, encryption is a mandatory security control. An organization’s security plan must be aware of and aligned with regulatory requirements, industry direction, and encryption capabilities.
Note Password use is central to the management of the encryption process, but the two concepts are not synonymous. Encryption relies on password authentication, but it addition- ally requires the use of a key to decrypt the information, even with a valid login or cracked password.
Public-Key Infrastructure
Public key cryptography, or asymmetric cryptography, gives the framework of standards, protocols, services, and technology to enable security providers to manage and deploy
A security system that provides trust. The basic components of public-key infrastructure (PKI) include certification authorities, lists of certificate revocation, and digital certificates. A PKI has to be built to support the basic components and scale the network to the requirements of the organization. Managing of public key cryptography is easily possible on public networks. Without a PKI in place, it is generally not feasible to use public key cryptography on public networks. This is because without a trusted third party issuing certificates, the certificates would not be trusted. In cryptography, X.509 is a standard that defines the format of public key certificates. X.509 certificates are used in many Internet protocols, including TLS/SSL, which is the basis for HTTPS, the secure protocol for browsing the web. They’re also used for offline applications, like electronic signatures.
An X.509 certificate contains a public key and an identity (a hostname, an organization, or an individual) and is either signed by a certificate authority or self-signed. When a certificate is signed by a trusted certificate authority or validated by other means, someone holding that certificate can rely on the public key it contains to establish secure communications with another party or validate documents digitally signed by the corresponding private key.
Note There are restrictions on cryptography export. Depending on what country or jurisdiction you work in, there may be restrictions placed on what you can obtain and use. Along with evaluating encryption for effectiveness in your business, make sure to evaluate government and trade restrictions as they apply to your choices.
Follow Us
https://www.facebook.com/INF0SAVVY
https://www.linkedin.com/company/14639279/admin/

