Identify and Classify Information and Assets
At a high level, the importance of identifying and classifying information assets as a first task in providing information security is significant. Without attending to these tasks, you will not be able to know where your assets are. You will not be able to know which assets are more valuable than others. The result will be an inefficient, costly information security plan attempting to secure all assets, with an assumption that the assets are located in all parts of the organization (local storage, shared storage, in the cloud, etc.). Worse, some assets requiring minimal protection, like public information, will be secured the same as confidential information. You will want to be able to locate, categorize, and differentiate the security approaches to your assets Creating the inventory of what assets an organization has, where the assets are, and who is responsible for the assets are foundational steps in establishing an information security asset management policy. Locating data has become more difficult because data as proliferated throughout the organization because of inexpensive local storage, mobile application development, and distributed data collection techniques. Mapping where data resides is a tough task, but necessary.
Laws and regulations are often the source of policy in organizations. There are significant reasons relative to jurisdictional and industry concerns that make understanding the prevailing legal and regulatory mandates important. Regulators around the globe have published standards with many commonalities. Following are some of the common regulatory regimes that formalize the classification and categorization of information:
- Canada: Security of Information Act
- China: Guarding State Secrets
- United Kingdom: Official Secrets Acts (OSA)
- United States: NIST Federal Information Processing Standard 199, “Standards for Security Categorization of Federal Information and Information Systems”
- United States: NIST Special Publication (SP) 800-60, “Guide for Mapping Types of Information and Information Systems to Security Categories” (this is considered the “how-to” manual for FIPS 199)
- United States: Committee on National Security Systems (CNSS) Instruction No. 1253, “Security Categorization and Control Selection for National Security Systems”
- European Union (EU): General Data Protection Regulation (GDPR)
- International healthcare: HL7 Informative Guidance Release 2, “Healthcare Privacy and Security Classification System (HCS)”
The content of the regulations and laws varies. Each concentrates on one or more aspects of data protection. The UK OSA, for example, is concerned with protection of state secrets and official information, and it informs data classification levels. The EU GDPR strengthens and unifies data protection and informs data flow policy. In the United States, the NIST FIPS 199 can be used for asset classification within the overall risk management process. The best organizational security policy will be developed using the relevant guidance as a foundational source. Once assets, including data, are classified according to sensitivity, a measure of the impact the loss of that data would have is made. The process of assigning a significance level to the confidentiality, integrity, or availability of data is called categorization. Categories can be as descriptive as high, medium, and low. The categories and classifications can be situational and unique based on organizational factors. Criteria such as industry and variations in acceptable use guidelines will result in categorizations that vary from organization to organization. Tip The information security asset management policy provides, at a high level, the relevant guidance for acceptable use of data, legal and regulatory considerations, and roles and responsibilities of data users in the organization, for example.
Note Review your organization’s data use procedures. Does your organization apply sufficiently stringent controls for all types of sensitive information? Some organizations control traditional business concerns or financial information, such as payroll, pricing, or billing rates, and less control for personally identifiable information (PII) or protected health information (PHI). It is appropriate for access to require multiple approval steps, for data sets to be segmented to reduce access, and for data to be available only on a need-to-know basis. Classification schemes depend on the organization.
Related Product : Personal Data Protection & General Data Protection Regulation Training & Certification
Asset Classification
Asset classification begins with conducting an inventory of assets and determining the responsible persons, or owners, for the assets. Assets contain data or provide information handling capabilities. Depending on the organization, examples of electronic types of assets are databases, email, storage media, and endpoint computers. Assets can be inventoried and protected that originate through oral communication, like voice recordings, although they are most commonly stored in digital format. Paper-based records are also assets to be protected. Records or documentation stored in file cabinets, desk drawers, or other physical filing systems can be classified based on sensitivity and value to the organization. You will have responsibility for including these paper assets in your information asset security plan.
Classifying the assets means categorizing and grouping assets by the level of sensitivity. The levels of classification dictate a minimum set of security controls the organization will use to protect the information. Keep in mind, the classification levels may call for protection that exceeds legal and regulatory requirements. A formal data policy is the primary mechanism through which an organization establishes classification levels, and then management can develop controls that provide sufficient protections against specific risks and threats it faces.
Benefits of Classification
Because it provides valuable insight into an environment, classification is a critical first step to better and more secure asset and data management. For a relatively simple process, the benefits are significant. Figure 2.1 depicts the major benefits of classification. The list is not comprehensive, and some organizations will find varying levels of benefit.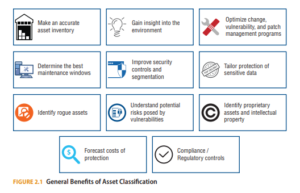
Qualitative vs. Quantitative Asset Value Analysis
A common way to value assets for classification (and categorization, discussed later in this chapter) is to use qualitative or quantitative risk analysis. Using objective measures and computing a numerical value describes quantitative approaches. This type of value is usually presented in currency, percentages, and specific numbers. Qualitative methodology differs in that measures are based on subjective judgment from assessors and organizational decision-makers. The way these assessments are communicated is in terms like high, medium, and low. The process is equivalent to the general risk management equation used throughout assessment of information risk. The value of the asset is dependent on the likelihood that a vulnerability will be exploited multiplied by the severity of the impact.
Tip Likelihood and probability are both used to describe how likely an event is to occur. Likelihood is relevant to qualitative analysis, and probability relates to quantitative. Under quantitative analysis, there are several types of equations that can be used. These formulas cover the expected loss for specific security risks and the value of safeguards to reduce the security risks:
- Annual Loss Expectancy (ALE) = Single Loss Expectancy (SLE) × Annual Rate of Occurrence (ARO)
- Single Loss Expectancy = Asset Value × Exposure Factor
- .0000000000000Safeguard Value = (ALE Before ? ALE After) ? Annual Cost of Countermeasure
To compute the ALE, the first step is to determine the value of the asset (AV). As an example, assume the AV equals $100,000. This helps determine the SLE because SLE equals AV multiplied by exposure factor (EF). EF is the probability the asset loss will occur. EF is expressed as a percentage in this example; if the EF is 30 percent, the SLE is $30,000, as $100,000 × 0.30 = $30,000. Annualized rate of occurrence (ARO) is the estimated frequency of the threat occurring in one year. To calculate ALE, ARO is multiplied by SLE. So, continuing the example, if SLE is $30,000 and the organization estimates ARO as 50 percent probability, the ALE is $15,000 or ($30,000 × (0.5)).
The organization thinks the vulnerability will be exploited once every two years. To figure out the safeguard value, some related computations are made by taking the ALE results from before the countermeasure was implemented and subtracting the ALE after the countermeasures were implemented. From that result, the annual cost of the countermeasure is subtracted. In the example, a countermeasure that costs more than $15,000 would need increased justification or would not be warranted. There are other considerations that may factor into this type of decision. Using a qualitative approach in combination with quantitative measures may provide the justification required.
Qualitative asset risk management uses the same general set of variables to measure risk such as asset value, threat frequency, impact, and safeguard effectiveness, but these elements are now measured in subjective terms such as high or low. The variables may still be expressed as numbers. High may equal 5 and low equals 1, for example. However, these numbers are not treated like numbers in a quantitative approach. If the values of high and low related to likelihood of asset compromise, a high equal to 5 does not indicate 5 times as likely as a low equal to 1. The ordinal nature of numbers is useful in demonstrating the order or rating of the categories comparatively.
There are advantages to using quantitative analysis:
- It is objective and uses real numbers for comparison.
- It is credible and meaningful and easily understood.
- It is aligned with financial considerations and tailored for cost-benefit analysis.
There are several disadvantages to quantitative analysis:
- It can be complex and intensive to calculate.
- It may provide a false sense of accuracy or precision.
- Measures and formulas can be miscalculated; results are not trusted.
Qualitative approaches have the following advantages:
- They are simple to measure and explain.
- They convey the necessary measures to identify the problem.
The disadvantages of qualitative approaches are as follows:
- They are subjective and dependent on the experience and judgment of the analyst.
- The assets can be over- or under-assessed.
- Recommendations are subjective.
- It’s hard to track progress.
Note Qualitative asset valuation cannot be used to directly justify costs through a cost– benefit risk analysis.
Asset Classification Levels
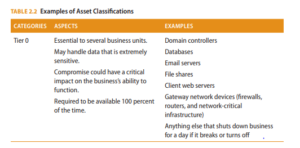
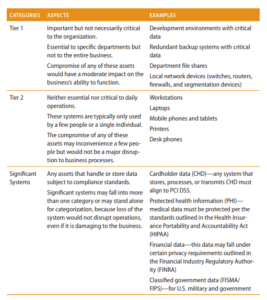
Assets should be identified and controlled based on their level of sensitivity. This allows similar assets to be grouped according to the value the organization places on the assets. The evaluation criteria can include the types of data the assets handle, the processes the assets accomplish, or both. There is no mandatory formula or nomenclature for asset classification categories. Each organization will have to establish names and sensitivity levels. Table 2.2 shows an example of types of asset classification. This is a notional framework for asset classification to illustrate how a portfolio of assets in an organization can be segmented into criticalities that map to high, medium, and low. The terms tier and significant systems are used as examples here and are not prescribed by a regulatory authority.
Follow Us
https://www.facebook.com/INF0SAVVY
https://www.linkedin.com/company/14639279/admin/

